 ongoing by Tim Bray
ongoing by Tim Bray
What is RSS2.com?
RSS2.com brings you the all the latest news from the best websites. Sit back, relax and enjoy.
Questions, suggestions or concerns can be sent to gserafini [at] gmail.com.
Bookmark this page by pressing CTRL+D
![]() Click here to save this page on del.icio.us
Click here to save this page on del.icio.us
December 2, 2019 Published ~ 5 years ago.
Strongly Typed Events
Back in 2016, in Message Processing Styles, I was sort of gloomy and negative about the notion of automated mapping between messages on the wire and strongly-typed programming data structures. Since we just launched a Schema Registry, and it’s got my fingerprints on it, I guess I must have changed my mind.
Eventing lessons
I’ve been mixed up in EventBridge, formerly known as CloudWatch Events, since it was scratchings on a whiteboard. It has a huge number of customers, including but not limited to the hundreds of thousands that run Lambda functions, and the volume of events per second flowing through the main buses are keeping a sizeable engineering team busy. This has taught me a few things.
First of all, events are strongly subject to Hyrum’s Law: With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody. Which is to say, once you’ve started shipping an event, it’s really hard, which is to say usually impossible, to change anything about it.
Second: Writing code to map back and forth between bits-on-the-wire and program data structures is a very bad use of developer time. Particularly when the messages on the wire are, as noted, very stable in practice.
Thus, the new schema registry. I’m not crazy about the name, because…
Schemas are boring
Nobody has ever read a message schema for pleasure, and very few for instruction. Among other things, most messages are in JSON, and I have repeatedly griped about the opacity and complexity of JSON Schema. So, why am I happy about the launch of a Schema Registry? Because it lets us do two useful things: Search and autocomplete.
Let’s talk about Autocomplete first. When I’m calling an API, I don’t have to remember the names of the events or their arguments, because my IDE does that for me. As of now, this is true for events as well; the IDE knows the names and types of the fields and sub-fields. This alone makes a schema registry useful. Or, to be precise, the code bindings and serializers were generate from the schema.
The search side is pretty simple. The schema registry is just a DynamoDB thing, nothing fancy about it. But we’ve wired up an ElasticSearch index so you can type random words at it to figure out which events have a field named “drama llama” or whatever else you need to deal with today.
Inference/Discovery
This is an absolutely necessary schema-registry feature that most people will never use. It turns out that writing schemas is a difficult and not terribly pleasant activity. Such activities should be automated, and the schema registry comes with a thing that looks at message streams and infers schemas for them. They told us we couldn’t call it an “Inferrer” because everyone thinks that means Machine Learning. So it’s called “schema discovery” and it’s not rocket science at all, people have been doing schema inference for years and there’s good open-source code out there.
So if you want to write a schema and jam it into the registry, go ahead. For most people, I think it’s going to be easier to send a large-enough sample of your messages and let the code do the work. At least it’ll get the commas in the right place. It turns out that if you don’t like the auto-generated schema, you can update it by hand; like I said, it’s just a simple database with versioning semantics.
Tricky bits
By which I mean, what could go wrong? Well, as I said above, events rarely change… except when they do. In particular, the JSON world tends to believe that you can always add a new field without breaking things. Which you can, until you’ve interposed strong types. This is a problem, but it has a good solution. When it comes to bits-on-the-wire protocols, there are essentially two philosophies: Must-Understand (receiving software should blow up if it sees anything unexpected in the data) and Must-Ignore (receiving software must tactfully ignore unexpected data in an incoming message). There are some classes of application where the content is so sensitive that Must-Understand is called for, but for the vast majority of Cloud-native apps, I’m pretty sure that Must-Ignore is a better choice.
Having said that, we probably need smooth support for both approaches. Let me make this concrete with an example. Suppose you’re a Java programmer writing a Lambda to process EC2 Instance State-change Notification events, and through the magic of the schema registry, you don’t have to parse the JSON, you just get handed an EC2InstanceStateChangeNotification object. So, what happens when EC2 decides to toss in a new field? There are three plausible options. First, throw an exception. Second, stick the extra data into some sort of
Mapstructure. Third, just pretend the extra data wasn’t there. None of these are insane.There’s another world out there where the bits-on-the-wire aren’t in JSON, they’re in a “binary” format like Avro or Protocol Buffers or whatever. In that world you really need schemas because unlike JSON, you just can’t process the data without one. In the specific (popular) case of Avro-on-Kafka, there’s a whole body of practice around “schema evolution”, where you can update schemas and automatically discover whether the change is backward-compatible for existing consumers. This sounds like something we should look at across the schemas space.
Tactical futures
Speaking of those binary formats, I absolutely do not believe that the current OpenAPI schema dialect is the be-all and end-all. Here’s a secret: The registry database has a SchemaType field and I’m absolutely sure that in future, it’s going to have more than one possible value.
Another to-do is supporting code bindings in languages other than the current Java, TypeScript, and Python. At the top of my list would be Go and C#, but I know there are members of other religions out there. And for the existing languages, we should make the integrations more native. For example, the Java bindings should be in Maven.
And of course, we need support in all the platform utilities: CloudFormation, SAM, CDK, Terraform, serverless.com, and any others that snuck in while I wasn’t looking.
Big futures
So, I seem to have had a change of worldview, from “JSON blobs on the wire are OK” to “It’s good to provide data types.” Having done that, everywhere I look around cloud-native apps I see things that deal with JSON blobs on the wire. Including a whole lot of AWS services. I’m beginning to think that more or less anything that deals with messages or events should have the option of viewing them as strongly-typed objects.
Which is going to be a whole lot of work, and not happen instantly. But as it says in Chapter 64 of the Dao De Jing: 千 里之行,始於足下 — “A journey of a thousand leagues begins with a single step”.
November 29, 2019 Published ~ 5 years ago.
Electric Boats
I love boating, but I hate the fact that powerboats guzzle loads of fossil fuel. I assuage my guilt by noting that the distance traveled is small — a couple of hours for each return trip to the cabin, and there are sadly less than twenty of those per year. Then I got into a discussion on /r/boating about whether electric boats are practical, so herewith some scratchpad calculations on that subject.
I’ve ridden on an electric boat, on the Daintree River in Queensland, on a small alligator-watching tour. This thing was flat and had room for maybe fifteen tourists under a canopy, necessary shelter from the brutal tropical sun; on top of the canopy were solar panels, which the pilot told me weren’t quite enough to run the boat up and down the river all day, he had to plug it in at night. The motor was a 70HP electric and our progress along the river was whisper-quiet; I loved it.
I should preface this by saying that I’m not a hull designer nor a battery technologist nor a marine propulsion engineer, so the calculations here have little more precision than Enrico Fermi’s famous atomic-bomb calculation. But possibly useful I think.
Narrowing the question
There are two classes of recreational motorboat: Those that go fast by planing, and those that cruise at hull speed, which is much slower and smoother. Typically, small motorboats plane and larger ones cruise. I’m going to consider my Jeanneau NC 795 as an example of a planing boat, and a Nordic Tug 32 as an example of a cruiser, because there’s one parked next to me and it’s a beautiful thing.
’Rithmetic
My car has a 90 kWh battery, of a size and weight that could be accommodated in either boat quite straightforwardly. A well-designed electric such as a Tesla typically burns 20 kWh/100km but you can’t use all the kWh in a battery, so you can reasonably expect a range of about 400km.
The Jeanneau gets about 1.1 km per liter of fuel while planing (it does two or three times better while cruising along at hull speed). Reviewers say that at 7-8 knots the Nordic burns about a gallon per hour, which my arithmetic says is 3.785 km/L.
A typical gas car gets about 10L / 100km, so 10 km/L. So the Nordic Tug is about 38% as efficient as turning fuel into km as a car, and the Jeanneau is only about 11% as efficient. (And of course both go much slower, but that’s not today’s issue.)
If the same is true for electric “fuel”, the battery that can take a Tesla 400km could take the Nordic tug about 150km and the Jeanneau a mere 44km.
Discussion
There are boats that get worse mileage than the Jeanneau, but they’re super-macho muscle boats or extravagant yachts the size of houses. So for recreational boats accessible to mere mortals, the Jeanneau, which is in a class called “Express Cruiser”, is kind of a worst-case, a comfy family carrier that can be made to go fast on the way to the cabin, but you pay for it.
So the tentative conclusion is that at the moment, batteries are not that attractive for express cruisers. But for tugboat-class craft designed for smoothness not speed, I’d say the time to start building them is now. Among other things, marine engine maintenance is a major pain in boaters’ butts, and electric engines need a whole lot less. On top of which they’re a lot smaller, and space is always at a premium out on the water.
Variations and Futures
The following are things likely to undermine the calculations above:
The Jeanneau could fit in quite a bit bigger battery than most cars; packing it into the hull so that the boat still performs well would be an interesting marine engineering problem.
The Nordic Tug could pretty easily fit in a battery two or three times that size and, at hull speed, I suspect it wouldn’t slow down much.
The torque curves of electric and gas engines are vastly different; which is to say, electrics don’t really have one. You have to get the Jeanneau’s engine up north of 4K RPM to really zoom along, which I suspect is not exactly fuel-optimized performance.
Related to the previous item, I wouldn’t be surprised if there were considerable gains you could pull out of the low-RPM/high-torque electric engine in terms of propeller design and perhaps hull shape.
Battery energy density is improving monotonically, but slowly.
Boats tend to spend their time out under the open sky and many have flat roofs you could put solar panels on to (slowly) recharge your batteries. In fact, many do already just for the 12V cabin batteries that run the fridge and lights.
I expect installation of Level 2 chargers on the dockside would require some innovation for safe operation in an exposed environment full of salt water. I doubt that it’d be practical to offer 50-100kW DC fast-charging gear at the gas barge.
I’ve long lusted after tugboat-style craft, but they’re expensive, bigger (thus moorage is hard to find), and go slower. Given a plausible electric offering, I think I could learn to live with that.
November 23, 2019 Published ~ 5 years ago.
Wolfe and Gika
Chelsea Wolfe I mean, and her opening act Thursday night was Ioanna Gika. It was exceptionally enjoyable, partly because nothing about it was wrong. Lovely music, great staging, good venue, exceptional sound. This happens rarely enough that it’s worth calling out when it does.
Chelsea Wolfe
Ms Wolfe has appeared on this blog multiple times. She has two modes: Acoustic, where the songs are ethereal splashes of complex slow-moving beauty; and electric, banshee keening nestled into a torrent of roaring guitar drone. Thursday night was sort of acoustic; Chelsea had an acoustic guitar and then a guy on keyboards and guitars.


I’ve seen her perform twice now, and both times it’s been very… dark. Thematically and then visually. After four hours or so in her presence, I’m sure I wouldn’t recognize her on the street. It was challenging fun to photograph.
The music was not quite like her acoustic records, in that the musical backdrop was electric and synthetic, and dark like the room. Her melodies don’t orbit in your head for weeks, but the orchestration and raw beauty of the sound palette are formidable, and then she is a wonderful singer, voice full of grace and power with an astonishing high register that she pours out with no effort and exactly when the song’s flow needs it.
An unexpected pleasure was when she left her platform, sat down beside her accompanist and, to a minimal slow chord rhythm, performed Joni Mitchell’s Woodstock, taking it pretty straight but digging deep into each note and soaring up into “we are golden…” — I got all emo.
Ioanna Gika
She wasn’t announced and I didn’t catch her name when she gave it, so I didn’t know who she was till I asked the Internet after the show. Like Chelsea, she performed with just a keyboard/guitar accompanist. Perhaps even the same one, there wasn’t enough light to tell. She had a minimal little device on a stand that could play keyboard, but what she mostly did with it was capture her own voice, load it up with reverb, then sing counterpoint against it.

Her music was quite a bit more dynamic than Wolfe’s even if she didn’t bring that voodoo intensity. Listening to her, I thought of the Cocteau Twins, and of Enya, and heard prog-rock echoes too. I really, really liked it and bought her CD Thalassa from the merch table. It’s great, but I actually liked the concert performance better; more intense, more complex, riskier. And also because of the sound.
Audio wow
The show was at the Vogue Theatre in Vancouver; I can’t remember the last time I was there, but it’s a nice room. I have to say this was the best live sound I’ve heard since the last time I heard unamplified acoustic music in a decent room, and I’ve never heard better live electric sound in my life that I can remember. I dunno what kind of microphones and signal chain they had, but the voices were full of three-dimensional artifacts, hints of chest and breath, not an atom of overload ever. Both women built huge low synth notes into their arrangements, placed with musical intelligence; these sounded like they were coming from the center of the earth, dark but crystal-clear.
More than a half-century into the era of live electric music, really great sound is still the exception not the rule. The touring-tech profession should be ashamed. And kudos to whoever did sound for the Wolfe/Gika gig.
November 17, 2019 Published ~ 5 years ago.
Bits On the Wire
Exactly 100% of everything on the Internet involves exchanging messages which represent items of interest to humans. These items can be classified into three baskets: One for “media” (images, sound, video), one for text (HTML, PDF, XML), and one for “objects” (chat messages, payments, love poems, order statuses). This is a survey of how Object data is encoded for transmission over the Internet. Discussed: JSON, binary formats like Avro and Protobufs, and the trade-offs. Much of what people believe to be true is not.
History sidebar
The first ever cross-systems data interchange format was ASN.1, still used in some low-level Internet protocols and crypto frameworks. ASN.1 had a pretty good data-type story, but not much in the way of labeling. Unfortunately, this was in the days before Open Source, so the ASN.1 software I encountered was slow, buggy, and expensive.
Then XML came along in 1998. It had no data-typing at all but sensibly labeled nested document-like data structures. More important, it had lots of fast solid open-source software you could download and use for free, so everybody started using it for everything.
Then sometime after 2005, a lot of people noticed JSON. The “O” stands for “Object” and for shipping objects around the network, it was way slicker than XML. By 2010 or so, the virtuous wrath of the RESTafarians had swept away the pathetic remnants of the WS-* cabal. Most REST APIs are JSON, so the Internet’s wires filled up with media, text, and JSON.
On JSON
I think there’s still more of it out there than anything else, if only because there are so many incumbent REST CRUD APIs that are humming along staying out of the way and getting shit done.
JSON pros:
Readers and writers are implemented in every computer language known to humankind, and they tend to interoperate correctly and frictionlessly with each other, particularly if you follow the interoperability guidelines in RFC 8259, which all the software I use seems to.
It does a pretty good job of modeling nested-record structures.
It’s all-text, so humans can read it, which is super extra helpful.
You can receive a JSON message you know nothing about and pick it apart successfully without knowing its schema, assuming it has one, which it probably doesn’t. So you can accomplish a task like “Pull out the item-count and item-price fields that are nested in the top-level order-detail field” with pretty good results given just a blob of raw JSON.
You can reliably distinguish between numbers, strings, booleans, and null.
JSON cons:
The type system is impoverished. There is no timestamp type, no way to know whether a number should be treated as an integer or float or Bignum, no way to signal when string values are really enums, and so on.
Numbers are specially impoverished; in general you should assume that your repertoire is that of an IEEE double-precision float (but without NaN or ∞) which is adequate for most purposes, as long as you’re OK with an integer range of ±253 (which you probably should be).
Since JSON is textual, there is a temptation to edit it by hand, and this is painful since it’s nearly impossible to get the commas in the right places. On top of which there are no comments.
JSON’s textuality, and the fact that it carries its field labels along, no matter how deeply nested and often repeated, suggest that it is unnecessarily verbose, particularly when numeric values are represented in textual form. Also, the text needs to be converted into binary form to be loaded into objects (or structs, or dicts) for processing by code in memory.
JSON doesn’t have a universally-accepted schema language. I have been publicly disappointed over “JSON Schema”, the leading contender in that space; it’s just not very good. For a long time, the popular Swagger (now OpenAPI) protocols for specifying APIs used a variant version of a years-old release of JSON Schema; those are stable and well-tooled.

Mainstream binary formats
I think that once you get past JSON, Apache Avro might be the largest non-text non-media consumer of network bandwidth. This is due to its being wired into Hadoop and, more recently, the surging volume of Kafka traffic. Confluent, the makers of Kafka, provide good Avro-specific tooling. Most people who use Avro seem to be reasonably happy with it.

Protobufs (short for “Protocol Buffers”) I think would be the next-biggest non-media eater of network bandwidth. It’s out of Google and is used in gRPC which, as an AWS employee, I occasionally get bitched at for not supporting. When I worked at Google I heard lots of whining about having to use Protobufs, and it’s fair to say that they are not universally loved.
Next in line would be Thrift, which is kind of abstract and includes its own RPC protocol and is out of Facebook and I’ve never been near it.
JSON vs binary
This is a super-interesting topic. It is frequently declaimed that only an idiot would use JSON for anything because it’s faster to translate back and forth between data types in memory with Avro/Protobufs/Thrift/Whatever (hereinafter “binary”) than it is with JSON, and because binary is hugely more compact. Also binary comes with schemas, unlike JSON. And furthermore, binary lets you use gRPC, which must be brilliant since it’s from Google, and so much faster because it’s compact and can stream. So, get with it!
Is binary more compact than JSON?
Yes, but it depends. In one respect, absolutely, because JSON carries all its field labels along with it.
Also, binary represents numbers as native hardware numbers, while JSON uses strings of decimal digits. Which must be faster, right? Except for your typical hardware number these days occupies 8 bytes if it’s a float, and I can write lots of interesting floats in less than 8 digits; or 4 bytes for integers, and I can… hold on, a smart binary encoder can switch between 1, 2, 4, and 8-byte representations. As for strings, they’re all just the same UTF-8 bytes either way. But binary should win big on enums, which can be represented as small numbers.
So let’s grant that binary is going to be more compact as long as your data isn’t mostly all strings, and the string values aren’t massively longer than the field labels. But maybe not as much as you thought.
Unless of course you compress. This changes the picture and there are a few more it-depends clauses, but compression, in those scenarios where you can afford it, probably reduces the difference dramatically. And if you really care about size enough that it affects your format choices, you should be seriously looking at compression, because there are lots of cases where you’ve got CPU to spare and are network-limited.
Is binary faster than JSON?
Yes, but it depends. Here’s an interesting benchmark from Auth0 showing that if you’re working in JavaScript, the fact that JSON is built-in to the platform makes Protobuf’s advantages mostly disappear; but in an equivalent Java app, protobuf wins big-time.
Whether or not your data is number- or string-heavy matters in this context too, because serializing or deserializing strings is just copying UTF-8bytes.
I mentioned gRPC above, and one aspect of speed heavily touted by the binary tribe is in protobufs-on-gRPC which, they say, is obviously much faster than JSON over HTTP. Except for HTTP is increasingly HTTP/2, with longer-lived connections and interleaved requests. And is soon going to be QUIC, with UDP and no streams at all. And I wonder how “obvious” the speed advantage of gRPC is going to be in that world?
I linked to that one benchmark just now but that path leads to a slippery slope; the Web is positively stuffed with serialization/deserialization benchmarks, many of them suffering from various combinations of bias and incompetence. Which raises a question:
Do speed and size matter?
Can I be seriously asking that question? Sure, because lots of times the size and processing speed of your serialization format just don’t matter in the slightest, because your app is bottlenecked on database, or on garbage collection, or on a matrix inversion or an FFT or whatever.
What you should do about this
Start with the simplest possible thing that could possibly work. Then benchmark using your data with your messaging patterns. In the possible but not terribly likely case that your message transmission and serialization is a limiting factor in what you’re trying to do, go shopping for a better data encoding.
The data format long tail
Amazon Ion has been around for years running big systems inside Amazon, and decloaked in 2015-16. It’s a JSON superset with a usefully-enriched type system that comes in fully interoperable binary and textual formats. It has a schema facility. I’ve never used Ion but people at Amazon whose opinion I respect swear by it. Among other things, it’s used heavily in QLDB, which is my personal favorite new AWS service of recent years.
CBOR is another binary format, also a superset of JSON. I am super-impressed with the encoding and tagging designs. It also has a schema facility called CDDL that I haven’t really looked at. CBOR has implementations in really a lot of different languages.
I know of one very busy data stream at AWS that’s running at a couple of million objects a second where you inject JSON and receive JSON, but the data in the pipe is CBOR because at that volume size really starts to matter. It helped that the service is implemented in Java and the popular Jackson library handles CBOR in a way that’s totally transparent to the developer.
I hadn’t really heard much about MessagePack until I was researching this piece. It’s yet another “efficient binary serialization format”. The thing that strikes me is that every single person who’s used it seems to have positive things to say, and I haven’t encountered a “why this sucks” rant of the form that it’s pretty easy to find for every other object encoding mentioned in this piece. Checking it out is on my to-do list.
While on the subject of efficient something something binary somethings, I should mention Cap’n Proto and FlatBuffers, both of which seem to be like Avro only more so, and make extravagant claims about how you can encode/decode in negative nanoseconds. Neither seems to have swept away the opposition yet, though.
[Shouldn’t you mention YAML? —Ed.]
[No, this piece is about data on the network. —T.]On Schemas
Binary really needs schemas to work, because unless you know what those bits all snuggled up together mean, you can’t un-snuggle them into your software’s data structures. This creates a problem because the sender and receiver need to use the same (or at least compatible) schemas, and, well, they’re in different places, aren’t they? Otherwise what’s the point of having messaging software?
Now there are some systems, for example Hadoop, where you deal with huge streams of records all of which are the same type. So you only have to communicate the schema once. A useful trick is to have the first record you send be the schema which then lets you reliably parse all the others.
Avro’s wire format on Kafka has a neat trick: The second through fifth byte encode a 4-byte integer that identifies the schema. The number has no meaning, the schema registry assigns them one-by-one as you add new schemas. So assuming both the sender and the receiver are using the same schema registry, everything should work out fine. One can imagine a world in which you might want to share schemas widely and give them globally-unique names. But those 32-bit numbers are deliciously compact and stylishly postmodern in their minimalism, no syntax to worry about.
Some factions of the developer population are disturbed and upset that a whole lot of JSON is processed by programmers who don’t trouble themselves much about schemas. Let me tell you a story about that.
Back in 2015, I was working on the AWS service that launched as CloudWatch Events and is now known as EventBridge. It carries events from a huge number of AWS services in a huger number of distinct types. When we were designing it, I was challenged “Shouldn’t we require schemas for all the event types?” I made the call that no, we shouldn’t, because we wanted to make it super-easy for AWS services to onboard, and in a lot of cases the events were generated by procedural code and never had a schema anyhow.
We’ve taken a lot of flak for that, but I think it was the right call, because we did onboard all those services and now there are a huge number of customers getting good value out of EventBridge. Having said that, I think it’d be a good idea at some future point to have schemas for those events to make developers’ lives easier.
Not that most developers actually care about schemas as such. But they would like autocomplete to work in their IDEs, and they’d like to make it easy to transmogrify a JSON blob into a nice programming-language object. And schemas make that possible.
But let’s not kid ourselves; schemas aren’t free. You have to coördinate between sender and receiver, and you have to worry what happens when someone wants to add a new field to a message type — but in raw JSON, you don’t have to worry, you just toss in the new field and things don’t break. Flexibility is a good thing.
Events, pub/sub, and inertia
Speaking of changes in message formats, here’s something I’ve learned in recent years while working on AWS eventing technology: It’s really hard to change them. Publish/subscribe is basic to event-driven software, and the whole point of pub/sub is that the event generator needn’t know, and doesn’t have to care, about who’s going to be catching and processing those events. This buys valuable decoupling between services; the bigger your apps get and the higher the traffic volume, the more valuable the decoupling becomes. But it also means that you really really can’t make any backward-incompatible changes in your event formats because you will for damn sure break downstream software you probably never knew existed. I speak from bitter experience here.
Now, if your messages are in JSON, you can probably get away with throwing in new fields. But almost certainly not if you’re using a binary encoding.
What this means in practice is that if you have a good reason to update your event format, you can go ahead and do it, but then you probably have to emit a stream of new-style events while you keep emitting the old-style events too, because if you cut them off, cue more downstream breakage.
The take-away is that if you’re going to start emitting events from a piece of software, put just as much care into it as you would as you do in specifying an API. Because event formats are a contract, too. And never forget Hyrum’s Law:
With a sufficient number of users of an API,
it does not matter what you promise in the contract:
all observable behaviors of your system
will be depended on by somebody.Messages too!
The single true answer to all questions about data encoding formats
“It depends.”
November 3, 2019 Published ~ 5 years ago.
Subscription Friction
At Canadian Thanksgiving, friends joined us at our cottage for turkey and the fixings. The food (what we made and what they brought) all came out great and we had happy stomachs. I did a lot of the cooking and wanted to check recipes and was brought face to horrified face with the failure of publishing to work on the Internet. The solution seems plain to me and this won’t be the first time I’ve offered it. But something really needs to be done.
What happened was, I wanted to refresh my memory on turkey and gravy. These are dishes one makes regularly but rarely and the details don’t stick to my mind: What’s the meat-thermometer reading for a stuffed bird, and what order do you deploy the drippings, roux, and giblet broth in for gravy?
It turns out the part of the Web where recipes live is a dystopian hellscape. Even though the medium seems made for the message: Lists, pictures, and search are built-in! Not to mention voting and hyperlinks. Anyone who thinks they’ve got a really great gravy procedure can tell the world, and as more people agree, the recipe should become easier to find.
Except for what you find is an SEO battle, red in tooth and claw, where recipe sites stinking of burn-rate terror plead for engagement and as a matter of principle make it really hard to get to that damn ingredients-list and step-by-step. Newsletter! Notifications! Survey! Also-see! Multidimensional parallax-enhanced five-way scrolling Single-Page Applications!
In fact, it bothered me so much that a few days later, I posted a nice simple chicken-kebab recipe just for that good feeling when you use the Web the way it was designed. I took the pictures, I wrote the text, and I posted it all on my own domain, and anyone who follows a link will have the words and pictures in front of their eyes right away, and there won’t be any popups of any kind.
But it’s not just recipes, obviously. It’s a disease that afflicts the larger community of those who try to add value to the Net and to our lives by sharing their stories and pictures and movies and poems and dreams, in the process we generally call “publishing”.
It isn’t working.
“Become a subscriber today!”
My words today are interspersed with pictures of the signs and signals that obscure an increasingly large proportion of the Web’s surface: Imminent-closing-paywall-gate warnings.
I think there is something that is glaringly, screamingly obvious that at this point needs to be said loudly and repeatedly:
This.
Will.
Not.
Scale.I suspect that a high proportion of my readers know this is true just from the feeling in their gut, but as an exercise in rhetoric let me offer some of the reasons why.
Subscription fatigue is setting in. I’ll make a spending decision, even a big one, quickly and without regrets when whatever it is feels like the right thing. But a subscription, another bill showing up on every credit-card statement… forever?
A very high proportion of the world’s curious-minded well-educated people subscribe to some subset of The Economist, the New York Times, the Guardian, the Washington Post, and the New Yorker. Most of us feel we’re subscribed enough.
There’s a huge class of publications who’ll put out a handful of articles every year that I want to read, but not remotely enough to justify a subscription.
The offers are sleazy. Whenever I read an absurdly low-cost subscription offer, I know the number showing up my bill is going to be a lot higher pretty damn quick.
Obviously it’s not just journalism. What madness makes huge companies think that people will sign up for Netflix and Hulu and HBO and Amazon Video and Apple TV+ and Disney? I’m sure I’ve forgotten a few, and even more sure that more are on the way.
This. Will. Not. Scale.
We need friction somewhere
Information may want to be free, but writers want to be paid. In a world where you can follow any link and read whatever it points at instantly and for free, writers are going to starve. It’s the writers I care about the most, but let’s not forget the designers and copy-editors and fact-checkers and accountants and so on.
People who write and gather and curate recipes want to be paid too.
How about advertising?
The Grand Theory of the Web long said that the money comes from advertising. After all, there’s always been lots of free information out there, and there still is if you’re willing to put up a TV antenna. The reality is that unless you’re Google or Facebook, advertising is deeply broken. My favorite exposition of why ads as they are today don’t work is by Josh Marshall in Data Lords: The Real Story of Big Data, Facebook and the Future of News. It’s important to note that Marshall isn’t arguing that Web advertising is inherently broken; just that the current Facebook/Google business model is so successful that they’re basically skimming all the profit off the top of the system, and in particular ripping the guts out of independent niche publishers.
If you think “I already knew that”, take a minute and read that “Data Lords” piece linked above; it’s not as obvious as you might think.
Marshall is the founder and publisher of Talking Points Memo, one of the best US left-wing political publications, and had the good fortune to recognize the dead-endness of advertising early on and, starting in 2012, made a hard pivot to subscriptions. They’ve been innovative and aggressive and executed well, and it looks like they have an excellent chance of staying in it for the long haul.
What we’re seeing now is that more or less every Web publication has, in the last couple of years, come to the same conclusion and is trying the same pivot. Only it’s obviously not going to work.
Because This. Will. Not. Scale.
Which way forward?
One helpful thing would be to fix advertising. It’s easy to hate the ad business and ad culture but at the end of the day they’re probably a necessary facilitator in a market economy. And hey, if they want to pay part of the cost of the publications I like to read, I’m down with that. I’m not smart enough to have designed a regulatory framework that would restore health to the market, but I don’t think it’s controversial to say that it’d be really great if someone did.
But it seems to me that there’s a more obvious way; let me buy stories one-at-a-time without signing up for a monthly-charge-forever. The idea is this: When I follow a link to a juicy-sounding story in, say, the Minneapolis Star-Tribune or the The Melbourne Age, instead of the avalanche of subscription wheedling, I get a standardized little popup saying “Ten cents to read this”, with several options: Yes or no on this piece, and Always-yes or Always-no for this publication. Someone is operating the service that makes this happen and will do an aggregate charge to my credit card every month.
Suppose the Net lights up because some site has got their hands on Donald Trump’s tax returns. Maybe when I follow that link, the standard popup asks me for a buck instead of a dime.
Subscriptions would still be possible and still make sense if you were reading a lot of pieces from some publication, and could come with benefits — for example, Josh Marshall’s Talking Points Memo offers a super-subscription which subtracts all the ads and makes the pages wonderfully fast and lightweight.
Is that even possible?
It’s not exactly a new idea. Something like it was originally proposed by Ted Nelson in Literary Machines in 1981. The fact that nobody’s made it work so far might make a reasonable person pessimistic as to whether anyone ever will.
Well, I’m here to tell you that on the technology side, we have the tools we need to build this. You could spend a bunch of time devising an Internet Standard protocol for subscription services and wrangle it through the IETF or W3C or somewhere, and that’s not a terrible idea, but I’d probably want to build the software first. With an Amazon-style two-pizza team and modern cloud infrastructure I’d have it on the air in 2020, no problem.
The one design constraint I’d impose would be that this thing would have to work at small scale, not just for the The Bigs. [Disclosure: Yes, I’m a blogger and I’d like us to be able to make a buck too.] But once again, I just don’t see it as hard.
Bootstrapping the business side would be tough because the publishing industry is led by people who not only are not focused on technology but suffer from unrealistic fantasies as to what it is and isn’t. It’d be dead easy for Amazon or Google to offer this as a service, but the publishing community would, rightly or wrongly, assume it to be another way to suck all the money out of the sector.
Maybe there’s a role here for a consortium or institute; or for some large far-sighted publisher with a stable of properties to build this for themselves but with careful attention to making attractive to the rest of the industry?
My advice would be to get working on it fast. Because ads are broken and burn rates are high and pivoting to subscriptions was a really great idea in 2014 but it’s too late for that now.
October 13, 2019 Published ~ 5 years ago.
Easy Reliable Chicken Kebabs
This involves a certain amount of chopping stuff up, also attention to hygiene, but requires no particular technical skill and has never ever failed to get rave reviews.
Infrastructure and ingredients
A barbecue. Charcoal is said to produce better flavor but gas is immensely faster and easier.
Skewers. Metal or wood, whatever.
Chicken. I’m lazy, I buy it skinless & boneless from the supermarket. Breasts are easier to work with but thighs come out a little better. A kg will satiate four large hungry people.
Lemons. You could use the stuff that comes in bottles but that would be lame. Juicing lemons is easy.
Olive oil. If you think it makes a difference you can pay up for “Extra Virgin”. I do recommend looking for a respectable brand because I gather there is some seriously sketchy stuff upstream of the liquid labeled as “olive oil” on many store shelves.
Garlic. You could be sincere and slice or mash it, or you could buy a jar of garlic paste or minced garlic at the aforementioned supermarket, as I do.
Black pepper. Fresh-ground really does make a difference.
Other things to go on the skewers. The only essential thing is onions (but shallots are better). Also popular: Small tomatoes, mushrooms, sweet peppers (Aussies: I mean capsicum).

The chopping part is kind of boring, so I watched the ALCS.
Safety note: Several of these steps require getting intimate with uncooked chicken. Which can contain the sort of microorganism that causes major unhappiness. So a hot-soap-and-water hand-wash is in order whenever you move from the raw-chicken part to any other part. And then give the part of the counter where you did the raw-chicken stuff a good scrub.
Procedure
First, you make the marinade. Mine is equal-ish parts olive oil and lemon juice, with several large dollops of garlic paste, and lashings of black pepper. If I have oregano (dried not fresh) handy I throw some in; if not I don’t worry about it. Mix vigorously. You need enough marinade to cover your chicken and a little bit goes a surprisingly long way. Say 3 juicy lemonsworth and the same or a little more olive oil.
Cut up your chicken. You want pieces of a size and shape that go comfortably on the skewer. I tend to favor smaller rather than larger to increase the surface-area ratio, because the surface is where the marinade soaks in.
Drop the chicken into the marinade and swish it around. Put it in the fridge and ignore it for a while. I think two or three hours is plenty, but purists do all this the day before. Important: Count the pieces as you cut them up.
Now we’re getting ready to cook. Here’s where you need to get quantitative. Figure out how many skewers you want to make (or maybe just how many you have) and look studiously blank while you sip a glass of preprandial wine and calculate how many pieces of chicken per skewer. Since each chicken chunk should have one or more non-meat items separating it from the next, you now have sufficient information to calculate how many pieces of (for example) onion, mushroom, pepper, and so on you need. The one I did today had three pieces of chicken, two pieces of onion, one piece of pepper, two pieces of mushroom, and two cherry-tomato halves (one red, one yellow) on each skewer. I had forty meat morsels, and I made twelve skewers for the four of us, so the veggie numbers were easy to work out.

Ready for the grill.
Stop here and, if you are using wooden skewers, drop them in a sink-full or pot-full of water to get somewhat fireproof.
Cut up all your vegetables and fungi. I like to grab a bunch of cereal bowls, one for each ingredient. I try to cut them roughly the same size as I did the chicken, so that when I put them on the barbecue you won’t have a big hunk of onion shielding the meat from the flame, or the other way around. If you have a compost bin, move it from wherever it is to where you’re slicing, to capture the waste.
OK, pull the meat out of the fridge. Pour the marinade down the drain. Grab a big plate to put the completed skewers on. Arrange the chicken and all the other skewer-fodder and the plate as seems best to you. I’m a soulless geek so I work out a repeatable skewer script (e.g. tomato, chicken, onion, mushroom, chicken, pepper, mushroom, chicken, onion, tomato) and stick with it.
At some point halfway through, wash your hands and go fire up the barbecue.
Once you’re done you’ll have a satisfying heap of skewers on the plate, and quite a bit of chicken pollution on your hands and the counter. If you miscalculated and there are bits of leftover vegetable or chicken stick the ones you can on skewers and throw the rest out, they’re unsanitary.
Slap ’em on the barbecue, wait till one side is done, turn ’em over, wait again, then enjoy. Tongs help. If you’ve kept the size of the chicken morsels down, then when one side is visibly seared I find it’s reliably cooked inside. Four or five minutes each side works for me, but that’s on my barbecue with my preparation habits. You do really need to make sure the chicken’s done.

Accompaniments
Rice works well. I like to toss asparagus or broccoli on the part of the barbecue that isn’t full of skewers, but whatever. White wine, or (wouldn’t have said this even a couple of years ago) a good artisanal cider.
Leftovers
There won’t be any. The lemon-soaked garlic-loaded flame-kissed skewer payloads are ravishing. And it’s hard to get this one wrong.
[Disclosure: The attentive observer will notice that the pictures are of a different batch than the one the text describes.]
October 6, 2019 Published ~ 5 years ago.
Records and Lenses
Sunday included more fun than the recent average — at my age, chilling is often more attractive than partying. Sunday featured vinyl, vintage lenses, Southern guitar boogie, and a photo-assignment. With pictures! (Which may be a little puzzling, but stay with me.)

What happened was, I noticed that there was a Fall 2019 Record Convention and on impulse took the e-bike crosstown to the glamorous (not really) Croation Cultural Centre. I strolled in the door of the big room with all the people and the nice lady said “You want the record convention or the camera convention? This is the cameras.” Who knew? So I went over to the other side and ended up buying five records: Willie Nelson’s Teatro (with Emmylou and Daniel Lanois), Howlin’ Wolf’s Big City Blues, Yellowman and Fathead’s Bad Boy Skanking, James Blood Ulmer’s Free Lancing, and Sons of Kemet’s Your Queen is a Reptile.
It was just a high-school-gym-sized room with a big square of tables facing outward facing the other big square against the walls facing inward, all the tables full of boxes full of LPs. I posted an appropriately lo-rez video on Instagram. A few of the vendors had organizing principles, ranging from genre to alphabet to price. Lots didn’t.
What a bunch of stoners. Except for a few fresh-faced hipsters and the odd grizzled geek like yours truly. Good clean fun.
Photopunk
Since I’d come all the way, I coughed up $5 for the camera show, which was pretty well maximum steampunk. Old cameras! Some with bellows and bulbs, some the size of your head. I have enough cameras but you can never have too many lenses. There wasn’t much chance of anything Fujifilm-related (it’s from this millennium) but I have a Pentax K-mount adapter and as I wrote in that context, “there are an astonishing number of excellent K-mount lenses in every imaginable length and width on the market.” So I walked around the tables saying “K-mount?” to anyone showing lenses and lots had some.

Protip: Nifty fifty
If you’re stingy and want to take lovely portraits it turns out that for basically any camera in the world you can get a K-mount adapter for your camera cheap, and then go to a show like this (or eBay or whatever) and pick up a classic Pentax 50mm F1.4 for almost no money and with a little practice and love, you’ll be making your friends and loved ones look better than they really do.
But I have a nifty fifty already. I’d got two thirds of the way around the camera trail and saw nothing interesting, but then there was this Mittel-Euro dude with an astonishingly small and slim 100mm F/2.8. He wanted $120 Canadian. I walked away and completed the orbit without turning up any gold, so I went back and offered him $100 and he took it. It turns out to be an M 100/2.8, i.e. probably 40 years old.

Isn’t it adorable?
Allstars!
Sunday evening I had tickets to see the North Mississippi Allstars. So I strapped the 100mm on the Fujifilm and thought I’d try for some electric-stage drama. Only the security guy took one look and said “gotta coat-check professional cameras.” Professional?! Uh…
Anyhow, the Allstars were just fine, post-Allmans southern boogie, more on the countrified side with a killer washboard solo (no, really) and really a lot of very solid guitar. Plus they played Down By The Riverside (“Ain’t gonna study war no more”) which always gets me choked up. I’d go if they came near you, assuming you like electric white-boy music.
Photocrit
It turns out that at Amazon Vancouver we’ve got a little photocritique social group, where someone deals out a weekly theme and we all post pix and suggest improvements to each other. This week’s theme is “long exposure”. So as soon as I got in the taxi home (For the Vancouver-savvy: up Main from the DTES to Riley Park), with a couple of drinks under my belt and a head full of electric guitar grace, I rolled down the backseat window, set the shutter to ⅛ second and the aperture to F/4, and took pictures of pretty well everything. Three made me smile.
And I think to myself… what a wonderful world.
October 5, 2019 Published ~ 5 years ago.
Discogs Pain
As I continue slowly ingesting the 900 classical LPs I inherited, I’ve developed a relationship with Discogs. It’s a good place to track your collection (here’s mine, in-progress). This is the story of my first attempt to use it to buy music, a laughable failure. It’s by way of public service, just leaving a marker, a warning others to be careful about charging into the marketplace.
There’s a lot to like about Discogs. The screens are unfussy and fast and their coverage of everything ever recorded is just awesome. The LP collection I’m working my way through has plenty of obscurities by no-hit wonders, but I’ve been through a couple hundred records now and only hit one that it didn’t already have (for your amusement: Music from The Golden Age of Silent Movies played by Gaylord Carter at the Mighty Wurlitzer Theater Organ).
Also, they’ve apparently taken a mere $2.5M in venture investment, show the world a human face, and seem to genuinely care about old recordings in a tone that’s enthusiast rather than unicorn-wannabe.
Fast Freight
Back when I was doing Songs of the Day, I wrote about Fast Freight, a standout on a generally-pretty-corny 1958 mono album by the Kingston Trio that I inherited from my Dad. It’s a lovely performance which I also use as an audio showpiece; when a technical friend looks at my audio setup and snottily wonders why I still play LPs, I use this to show what the technology can do. Which usually works pretty well

Only Dad’s copy’s getting kind of ratty, and it occurred to me that maybe I could use Discogs to replace it. Sure enough, there were plenty on sale, so I picked one on the basis that it was advertised as having “near-mint” surfaces and was offered by a seller with a good rep.
So here’s my sad story:
I jumped through the Discogs hoops, not terrible at all, and placed the order.
Almost instantly, the site came back saying the status was “Invoice sent”. I didn’t see any invoice on the screen or in my Discogs account or my email in-basket. I decided to wait, on the assumption it would show up.
A few days later, Discogs popped up a notice saying that payment was due and unless I did so within a day or so my reputation would suffer.
I fired off a barrage of messages to Discogs support and the seller saying, in effect “WTF, I want to pay, how do I pay?” Discogs was pretty prompt getting back, said “probably best to reach out to the seller.”
The seller eventually got back to me and said if I wasn’t set up on Discogs’ internal payment system, he could take PayPal. I poked around Discogs.com and couldn’t figure out how to set up to use their payment system (still can’t). He asked me to send it marked “friends and family” so “PayPal wouldn’t hold it”.
I sent him the money and PayPal did indeed put it on hold, and had deducted a big service fee. So he refunded it to me. This led to a hilarious, where by “hilarious” I mean “really irritating”, sequence of attempts to pay him, by splitting the payment up, by marking smaller amounts “Friends and family”, and I forget the rest. None of it worked, PayPal was determined not to let my money get through to him. This leads me to wonder how he’d got himself on PayPal’s hold-the-payments list.
The seller also said that somewhere along the way I’d accidentally left negative feedback, could I please remove it? I couldn’t find any feedback anywhere.
Finally, by routing PayPal to a different email address, he got the money and let me know he’d sent the record.
A reasonable amount of time later, the record showed up. It was all scratched to ratshit and there was a big cut in the middle of Fast Freight so that the needle kept skipping back.
My Discogs account still has a permanent notification that payment is outstanding for this order and my reputation is in danger.
I’m Doing It Wrong
That’s the only conclusion I can draw. I need to go and research how to buy things on Discogs without getting taken for a ride. I suspect it’s possible but it should be easier.
September 28, 2019 Published ~ 5 years ago.
At the Climate Strike
I went and so did lots of others, but many couldn’t so I thought I’d try to share the scale and the feel.

(Mounted on a hockey stick)
I’m pretty old and cynical and still, this felt like it mattered. Even though it was good-humored and consciously funny. Partly it was just the scale — one of our big north-south thoroughfares full of streaming strikers it seemed forever, but they say the peak of the parade only lasted an hour and a half. The police estimated a hundred thousand but they are prone to undercounting based on an institutional fear of too many people in one place going the same direction. Having said that, the cops were pretty exellent, see below.
Many spectated.

The crowd was young, people whom they say don’t vote, and anyhow many were too young to vote. But their good-humored passion could not fail to lift hearts. Well, mine anyhow.
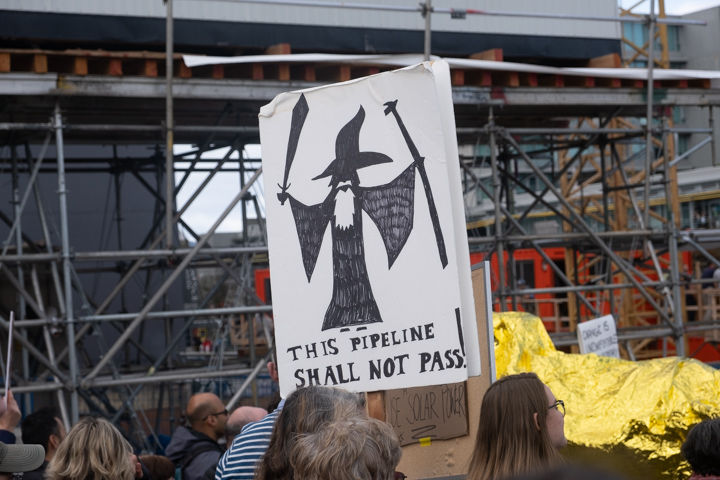
Not that I was the only greybeard. If you’d subtracted the kids it still would have been a pretty big deal.
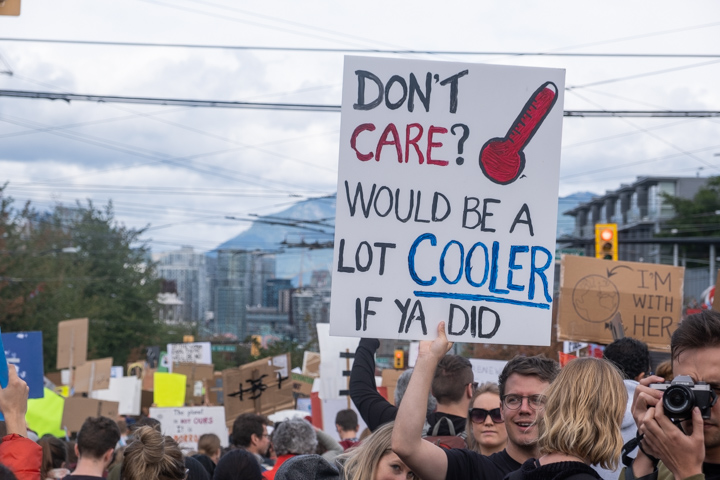
I didn’t get a picture of the kid with the sign saying “I’m skipping Fortnite to be here!”

Once we got downtown, all the balconies and windows were full of people watching.

The most popular chant was “What do we want?” “Climate justice!” “When do we want it?” “Now!” My voice is hoarse today. That chant is a common variation on a very old theme but it was the first time I’ve been part of it. After a little practice, the crowd gets into a more practiced and powerful rhythm; in particular the “Now!” becomes an explosion, elating to be part of and maybe a little scary for the intended audience. I hope so anyhow.

There was this skinny little guy walking along, well under 10, whose chant was “Want to play in the snow? Stop global warming?” Pretty pedestrian, but he had a surprising volume and amazing endurance, he kept going and going and going and eventually the rhythm was fascinating and voices around him stilled.

I was shocked that Justin Trudeau, pipeline promoter, had the gall to appear at the Montréal strike. His smarmy-robot mantra about “The environment and the economy” isn’t fooling anyone any more. The best route to a sound twenty-first century economy requires creative destruction centered on the fossil-fuel sector. There’s plenty of capital and demand and opportunity to fill in behind, but first we have to step away from petroleum extraction, big-time.

Towards the end of the route, the crowd started piling up and I couldn’t make any forward progress. Somewhere up ahead I could hear speeches, but the point had been made and my feet were killing me, so I took the train home. Hats off to Vancouver’s cops and TransLink’s helpers who kept the throngs moving through City Center station and damn did they ever have those trains shuttling through on the double-quick. I admire calm-faced competence when I see it.

Everybody was self-congratulatory about the nonviolence and good cheer, and unlike other recent events, there are no counter-demonstrators in evidence. The contras are all behind the walls of the glass towers our chants were echoing off of, and those guys are way too busy to pay attention.
When the waters start rising and the crops start failing, the glass will start breaking.

A few signs here and there were really obscene, a repeated theme of, uh, let’s phrase it as inappropriate sexual relations involving a female parent. 100% of the people carrying these were women.

And of course, there were a variety of other causes looking for listeners in what smells like the progressive mainstream. Communists, vegans, co-operative housing advocates, I even saw a sign for the IWW, which I thought as a sort of historically-significant exotic fringe thing when I was a hot-headed young leftist 40 years ago. Seems the Wobblies have staying power.

The cops had been smart, blocked access to the Cambie bridge and its feeders well in advance. Things went a little sideways downtown where a lot of people were trying to commute or go shopping and unfortunately got on the wrong cross-street and ended up motionless for a couple of hours while the strikers streamed past. I hope nobody’s life was seriously damaged, but a lot of lives are going to be seriously damaged if we don’t get our climate-change act together.
The buses were blocked on Granville Street.

You’ve probably heard of airplane boneyards, places in the desert where they park hundreds of disused unwanted jet planes? When sanity sets in and it becomes just too expensive for people to waste energy the way internal-combustion cars do, there’ll be auto boneyards too.
September 25, 2019 Published ~ 5 years ago.
On Sharding
If you need to handle really a lot of traffic, there’s only one way to do it: sharding. Which is to say, splitting up the incoming requests among as many hosts (or Lambda functions, or message brokers, or data streams) as you need. Once you get this working you can handle an essentially unlimited request volume. Of course, you have to make choices on how you’re going to divide up the traffic among the shards. I’ve had intense exposure to the options since I came to work at AWS.
Random spray
This is the simplest thing imaginable. For each message, you make a UUID and use it as the Partition Key (if your downstream uses that for sharding), otherwise just pick a target shard using your favorite random number generator.
There’s a lot to like about it. Your front-end can be dumb and stateless and fast. The load will get dealt out evenly among the shards. Spoiler alert: I think this is a good choice and you should do it if you can possibly can.
A common variation on this theme involves auto-scaling. For example, if you have a fleet of hosts processing messages from an SQS queue, auto-scaling the fleet size based on the queue depth is a fairly common practice. Once again, admirably simple.
“Smart” sharding
The idea is that you do extra work to avoid problems, for example some shards getting overloaded and others being idle. Another kind of problem is one of your upstream sources sending “poison pill” messages that cause the receiving shard to lock up or otherwise misbehave
Load-sensitivity is one “smart” approach. The idea is that you keep track of the load on each shard, and selectively route traffic to the lightly-loaded ones and away from the busy ones. Simplest thing is, if you have some sort of load metric, always pick the shard with the lowest value.
I’ve seen this done, and work OK. But it isn’t that easy. You have to figure out a meaningful load metric (queue depth? how much traffic received recently? CPU load?) and communicate that from each shard to the front end.
If poison pills are your worry — this is not rare at all — the smartest approach is usually shuffle sharding. See Colm MacCárthaigh’s awesome thread on the subject, which you should go read if you haven’t already. He has pretty pictures (see below for one I stole) and math too!

Affinity
Also known as “session affinity”. Another term you sometimes hear is “sticky sessions”; for a discussion see this article over at Red Hat. The idea is that you route all the events from the same upstream source to the same shard, by using an account number or session identifier of some sort as a partition key.
Affinity is attractive: If all the clickstream clicks from the same user or state-change events from the same workflow or whatever go to the same host, you can hold the relevant state in that host’s memory, which means you can respond faster and hit your database less hard.
Ladies, enbies, gentlemen, and others: I’ve had really lousy luck with affinity in sharding. Lots of things can go wrong. The most obvious: When traffic isn’t evenly distributed among upstream sources.
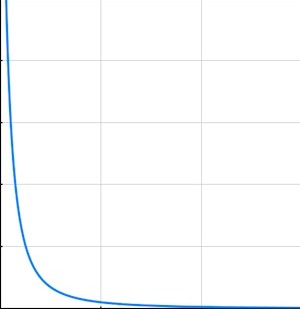
One time I was working with a stream of AWS customer events, and I thought it’d be smart to deal them out to Kinesis shards by account number. That was bad — the messages per second per account rate was distributed across account numbers in a classic inverse-square curve like the one in the margin. To make this concrete, in one of the early tests I noticed that the top 10 account numbers accounted for half the traffic. Ouch. (I don’t think this was a rare situation, I think it’s probably common as dirt.)
The general lesson is that if you unfortunately send too many “hot” upstream sources to the same shard, it’s easy to overload it. The worst case of this is when you get a single “whale” customer whose traffic is too much for any single shard.
So in this situation I’m talking about, we switched to random-spray, and the whole system settled down and ran nice and smooth. Except for, processing each message required consulting a database keyed by account number and the database bills got kind of high.
So I got what I thought was a brilliant idea, hid in a corner, and wrote a “best-effort affinity” library that tried to cluster requests for each customer on as few shards as possible. It seemed to work and our database bills went down by a factor of six and I felt smart.
Since then, it’s turned into a nightmare. There’s all sorts of special-case code to deal with extra-big whales and sudden surges and other corner cases we didn’t think of. Now people roll their eyes when smoke starts coming out of the service and mutter “that affinity thing”. They’re usually too polite to say “Tim’s dumb affinity code”.
That’s not all, folks
Here’s another way things can go wrong: What happens when you have session affinity, and you have per-session state built up in some host, and then that host goes down? (Not necessarily a crash, maybe you just have to patch the software.)
Now, because you’re a good designer, you’ve been writing all your updates to a journal of some sort, so when your shard goes pear-shaped, you find another host for it and replay the journal and you’re back in business.
To accomplish this you need to:
Reliably detect when a node fails. As opposed to being stuck in a long GC cycle, or waiting for a slow dependency.
Find a new host to place the shard on.
Find the right journal and replay it to reconstruct all the lost state.
Anyone can see this takes work. It can be done. It is being done inside a well-known AWS service I sit near. But the code isn’t simple at all, and on-call people sigh and mutter “shard migration” in exactly the same tone of voice they use for “Tim’s dumb affinity code.”
But the database!
So am I saying that storing state in shards is a no-no, that we should all go back to stateless random spray and pay the cost in time and compute to refresh our state on every damn message?
Well yeah, if you can. That fleet running my dumb affinity code? Turns out when we reduced the database bills by a factor of six we saved (blush) a laughably small amount of money.
What about latency, then? Well, if you were using a partition key for sharding, you can probably use it for retrieving state from a key/value store, like DynamoDB or Cassandra or Mongo. When things are set up well, you can expect steady-state retrieval latencies in the single-digit milliseconds. You might be able to use a caching accelerator like DynamoDB’s DAX and do a lot better.
In fact, if the sessions you might have tried to shard on have that inverse-square behavior I was talking about, where a small number of keys cover a high proportion of the traffic, that might actually help the caching work better.
But the cache is a distraction. The performance you’re going to get will depend on your record sizes and update patterns and anyhow you probabl don’t care about the mean or median as much as the P99.
Which is to say, run some tests. You might just find that you’re getting enough performance out of your database that you can random-spray across your shards, have a stateless front-end and auto-scaled back-end and sleep sound at night because your nice simple system pretty well takes care of itself.
Feed Information for ongoing by Tim Bray
- Feed URL: http://www.tbray.org/ongoing/ongoing.atom
- Bookmark: http://rss2.com/feeds/ongoing